
GenAI skaliert nicht ohne Fundament – was Sie jetzt für eine erfolgreiche KI-Transformation beachten müssen.
Instantly break down data silos.
Unify ERP, CRM, IoT, SCM, and any other system into one live, semantic knowledge graph — without moving the data. (Powered by our federation-first architecture and ontology-driven modeling)
Capture your knowledge forever.
Every query, answer, and refinement expands your organization’s shared knowledge — making your AI and your teams better over time. (Enabled by our persistent semantic graph and reusable logic)
- ANALYTICS PLATFORM -
Conversational AI you can trust - grounded in your data.
Bessere Modelleallein reichen nicht. Damit KI im Unternehmen verlässlich funktioniert, brauchtsie eine Grundlage:
Unternehmenswissen in maschinenlesbarer Form. Die Datenmüssen vernetzt, konsistent und jederzeit abrufbar sein. Genau das macht einKnowledge Layer.
Der KnowledgeLayer d.AP überführt Fakten, Regeln und Zusammenhänge aus Ihren Systemen ineinen semantischen Knowledge Graph. Dadurch entsteht das Fundament für jedenAgenten, Copiloten und jedes KI-System. Vendor-neutral, auf offenen Standards,als echtes Unternehmens-Asset.


- ANALYTICS DASHBOARD -
In diesemWebinar lernen Sie:
- warum ein Knowledge Layer dieentscheidende Voraussetzung für skalierbare KI ist
- was ein Knowledge Layer ist und wie ersich von Datenkatalog, Data Mesh und RAG unterscheidet
- wie d.AP Unternehmenswissen in eineOntologie überführt und als Knowledge Graph in Echtzeit bereitstellt
- wie ein Knowledge Layer konkret aussiehtund wie man ihn Schritt für Schritt aufbaut
- KNOWLEDGE GRAPH PLATFORM -
Wer für GenAI dasnotwendige Fundament bereitstellen will, beginnt genau hier.
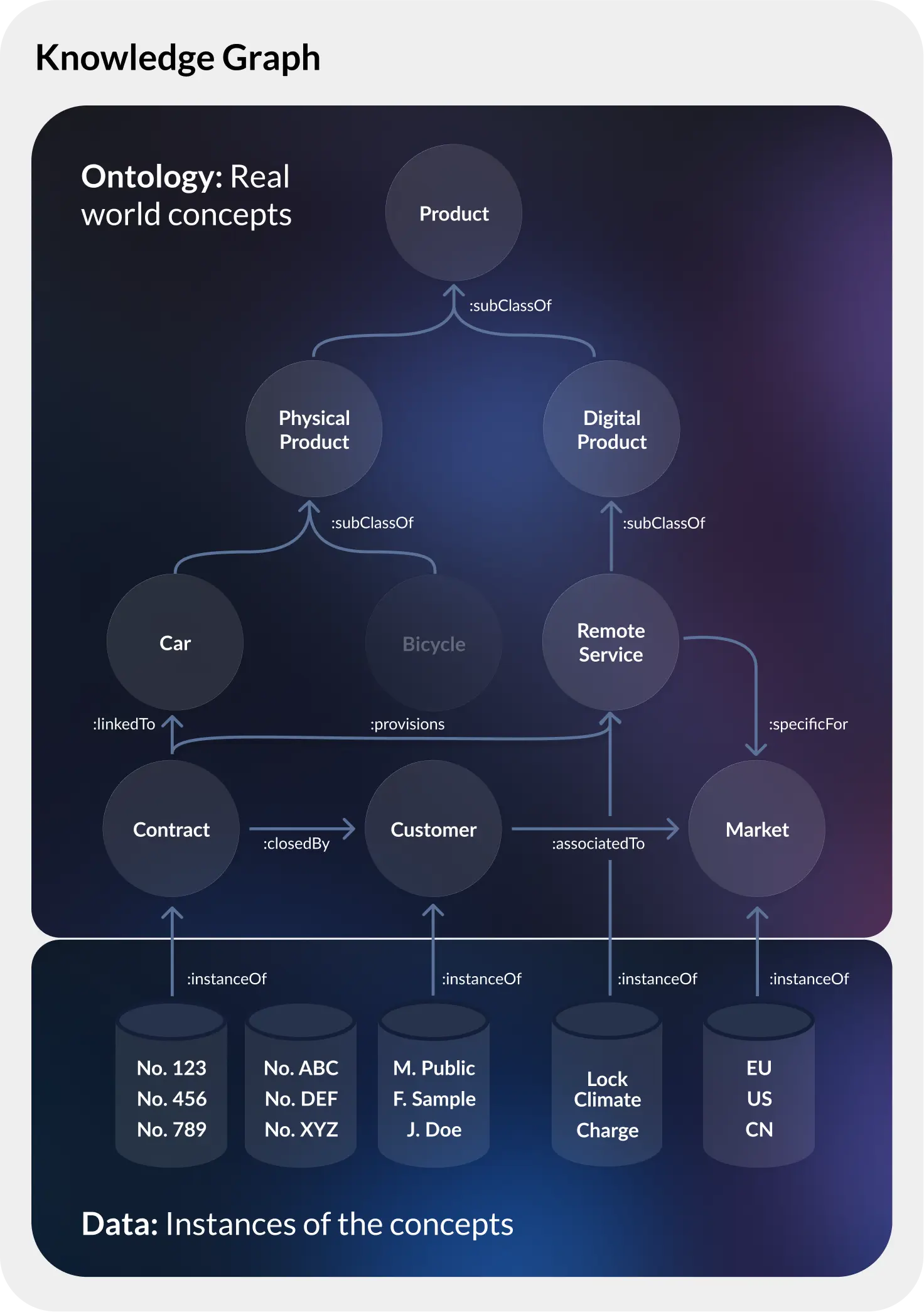
The beating heart of d.AP - integrating all enterprise data sources in a live, RDF-based federated knowledge graph. No duplication. No moving of existing systems of record, only a consistent, explainable and ready-for-AI view of your enterprise.
- Ontology management
Define and evolve your business vocabulary without breaking the model. - Federated real-time queries
Live access to ERP, MES, IoT, CRM and more. - Query management & reasoning
Powerful, explainable graph queries for any use case. - Graph analytics & write-back
From insight to action in the same environment. - Open-source standards
OWL is our language for interoperability with the world. - Enterprise ready
Secure, scalable and adhering to the highest enterprise-IT standards.
What our clients say about us.

FAQs.
We answer your questions in advance. We've missed something? Let us know.
A Knowledge Graph enriches your data — including data products — by explicitly describing them and their relationships in a form that is both human- and machine-readable. It links the actual data (facts) with its metadata, connecting the model directly to each data instance. This enables reasoning (inference) over the model to derive new facts and uncover insights that aren’t explicitly stored in the underlying data.
Yes. Knowledge Graphs — and therefore our solution — do not replace operational data storage or analytical data warehouses. They complement existing infrastructure by creating a semantic link between business entities and the underlying data, enabling cross-system understanding and integration.
A real Knowledge Graph gives the LLM direct semantic access, allowing it to query, reason, and generate answers from the graph itself. Graph-RAG, by contrast, retrieves relevant graph data first, converts it to contextual text, and passes it to the LLM — which then works only with that excerpt, without direct reasoning over the graph.
The Knowledge Graph (e.g., RDF-based) is exposed via a SPARQL endpoint. An agent translates natural-language queries into formal graph queries, retrieves the results, and returns them to the LLM. The LLM acts as a semantic interpreter — deciding when to query, processing the results, and generating accurate, natural-language answers.
The first use case is typically implemented within 3 months. Subsequent use cases can often be rolled out faster, building on the established data integration and ontology.
Yes. The platform is designed so decentralized teams can model ontologies, integrate data, and use it independently without relying on us. We fully adopt open standards and widely used technologies to ensure flexibility and interoperability.
Our pricing model combines one-time implementation services with a usage-based monthly fee:
- Implementation (Professional Services): Initial setup, including data integration and ontology modeling, typically costs between €50,000 and €150,000, depending on complexity and scope.
- Monthly fee (Usage-based): The ongoing cost depends on actual usage and cannot be stated as a fixed amount. For most enterprises, the monthly fee per use case ranges between €5,000 and €20,000.
Ontologies represent abstract concepts, relationships, and rules, which generally remain stable over long periods (e.g., “Employee” → “belongs to” → “Team”). Facts, however, can change (“Alice lives in Berlin” → “Alice lives in Leipzig”). The platform ensures fact freshness by integrating data directly from the authoritative sources for each use case.
Yes. During an active conversation, the AI remembers your earlier questions and answers. You can refer back to previous points (“What did I mean earlier by X?”) and maintain context for the duration of the chat. Once you start a new session, the context is lost, unless you use a version with memory, which retains selected facts about you but not full conversation histories.
That approach shifts complexity elsewhere and risks instability in dynamic, multi-agent systems. It also reinforces silos, since the supervising agent cannot see into each agent’s inner logic. A Knowledge Graph, especially one with a broad, iteratively expanded ontology, centralizes cross-domain knowledge and ensures consistency—similar to the “T-shaped skills” concept.
Think of it as assembly language vs. a high-level language: most platforms enrich SQL with additional metadata to address gaps in relational schema context, often functioning as federated SQL query engines. Their semantics are typically derived bottom-up from the physical data model and don’t follow universal business logic or RDF standards. Our approach is top-down, grounded in ontologies and open standards, ensuring interoperability and business-aligned semantics.

