Enterprises do not typically fail because they lack data. They tend to struggle because data is fragmented, inconsistently defined, and slow to turn into decisions. Traditional data architectures optimize for storage and movement. They do not optimize for meaning, trust, or reuse.
Federation has matured. Real-time, zero/low-ETL access is now viable at scale. AI raised the bar, as ungoverned, semantically weak data breaks GenAI initiatives. Decision velocity matters, because business teams cannot wait weeks for reconciled datasets. Finally, architectural fatigue is real. Organizations cannot keep rebuilding brittle pipelines for every new question.
This guide covers enterprise-grade unified data fabric platforms. It outlines buyer-relevant trade-offs such as federation versus centralization, semantics, governance, and time-to-value. It includes platforms used to support analytics, AI, operational decisions, and cross-domain use cases.
TL;DR: the Best Unified Enterprise Data Fabric Solutions are:
- d.AP by digetiers (d.AP): Best for semantic, decision-centric data fabrics. It unifies data via ontologies to deliver explainable decisions.
- Denodo: Best for enterprise-scale data virtualization and logical data fabric architectures.
- Starburst: Best for query-driven data fabrics built on distributed SQL.
- Informatica IDMC: Best for governed, metadata-driven data fabric programs in large, regulated enterprises.
- IBM Cloud Pak for Data: Best for platform-centric fabrics with hybrid deployment needs.
- Talend Data Fabric (Qlik): Best for integration-led data fabrics with embedded data quality.
The enterprise reality that forces data fabric adoption
Unified data fabrics only matter when they remove recurring friction in cross-domain delivery. These are the operational patterns that usually force enterprises to move from ad hoc integration to a fabric operating model.
The 5 recurring problems unified data fabrics address
- Fragmented data estates slow down cross-domain work. Teams spend cycles aligning sources rather than answering questions, which causes backlogs.
- ETL sprawl creates brittle pipelines and high maintenance costs. New use cases often trigger new jobs, which creates new breakpoints and ownership gaps.
- Inconsistent definitions drive metric disputes and lower trust. Finance and Ops report different numbers. Escalations replace strategy.
- Slow access blocks analytics and causes AI bottlenecks. Data engineering backlogs grow. AI teams wait on access, cleanup, and approvals.
- Poor reuse forces repeated rebuilds. Teams recreate the same joins, mappings, and metric logic across different tools. Redundancy slows delivery and increases risk.
What’s changed?
Data fabrics have moved from an architecture concept to an operating model. Federation is now practical, not theoretical. AI demands governed, semantically rich data access. Enterprises prioritize reuse of logic, not just reuse of data.
What counts as a “unified enterprise data fabric”
Buyers often evaluate “data fabric” platforms that solve different problems, then struggle to compare outcomes. The archetypes below separate tools by how they unify access, governance, and meaning.
The three data fabric archetypes buyers confuse
Virtualization-first data fabrics focus on fast access without data movement. You query multiple systems through a unified layer. The strength is immediate access. The risk is weak semantics and limited decision context, as business meaning often lives outside the fabric. Denodo is a common example here.
Metadata-driven data fabrics focus on governance and discoverability. You get catalog, lineage, and policy controls across the program. The strength is broad control. The risk is limited runtime intelligence. Design-time governance does not always translate into inspectable outputs. Informatica IDMC fits this category.
Semantic and decision-centric data fabrics focus on meaning. You unify data by shared definitions and logic, often exposing results in forms business teams use directly. The strength is shared meaning, explainability, and reuse. The risk is the higher modeling discipline required. d.AP fits this category.
Minimum enterprise-grade data fabric capabilities checklist
This checklist defines the baseline capabilities that separate an enterprise-ready data fabric from a set of point tools. Use it to screen vendors early. If a platform falls short on any of these, expect higher build effort, weaker trust, or slower time-to-value.
- Federated and/or hybrid data access.
- Semantic modeling and shared business definitions.
- Governance and lineage at query time.
- Explainability of transformations and metrics.
- Support for analytics, AI, and operational consumption.
- Security, IAM, and deployment flexibility.
Buyer evaluation framework
Once you know which archetype fits your situation, the next step is scoring platforms against your outcomes and constraints. This framework keeps evaluation anchored in decision impact, not feature claims.
Primary outcome you’re buying
Data fabrics succeed when they shorten the path from question to answer. Start by naming the outcome.
- If you need faster cross-domain analytics, your platform choice will bias toward federation and query performance.
- If you need consistent enterprise KPIs, semantics, governance, and reuse matter more than raw speed.
- If you need AI-ready data access, you are buying governed retrieval, traceability, and reusable logic.
- If you need reduced data engineering backlog, look for platforms that cut the cycle where every new question requires a new pipeline.
- If you need operational decision support, evaluate how outputs become workflows, APIs, and explainable decision paths.
Data integration posture
Federated / zero-ETL offers the fastest access but governance must be proven under load. Cached or materialized provides predictable performance but risks staleness. Hybrid allows you to federate broadly and materialize what is critical.
Semantic maturity required
Schema-on-read pushes meaning downstream. Ontology-driven unifies meaning at the fabric layer. You must define who owns the definition and how disputes are resolved.
Explainability & trust
Users need to inspect how results are produced. Metrics must be reusable across BI and AI. Audit trails should link the decision output to the data source and definition.
Consumption & operationalization
Ensure the fabric supports your consumption channels: BI and dashboards, APIs and downstream apps, AI and agent consumption, or data products.
Security, deployment & compliance
Shortlists often fail here. Define requirements early for SaaS versus VPC, fine-grained access controls, and regulatory alignment.
Time-to-value & organizational effort
Pilot timelines depend on whether you define meaning or just unify access. Required skill sets differ between engineers and semantic owners. Ongoing ownership models matter more than tools.
Shortlist: The Best Unified Enterprise Data Fabric Solutions
1. d.AP by digetiers (d.AP)
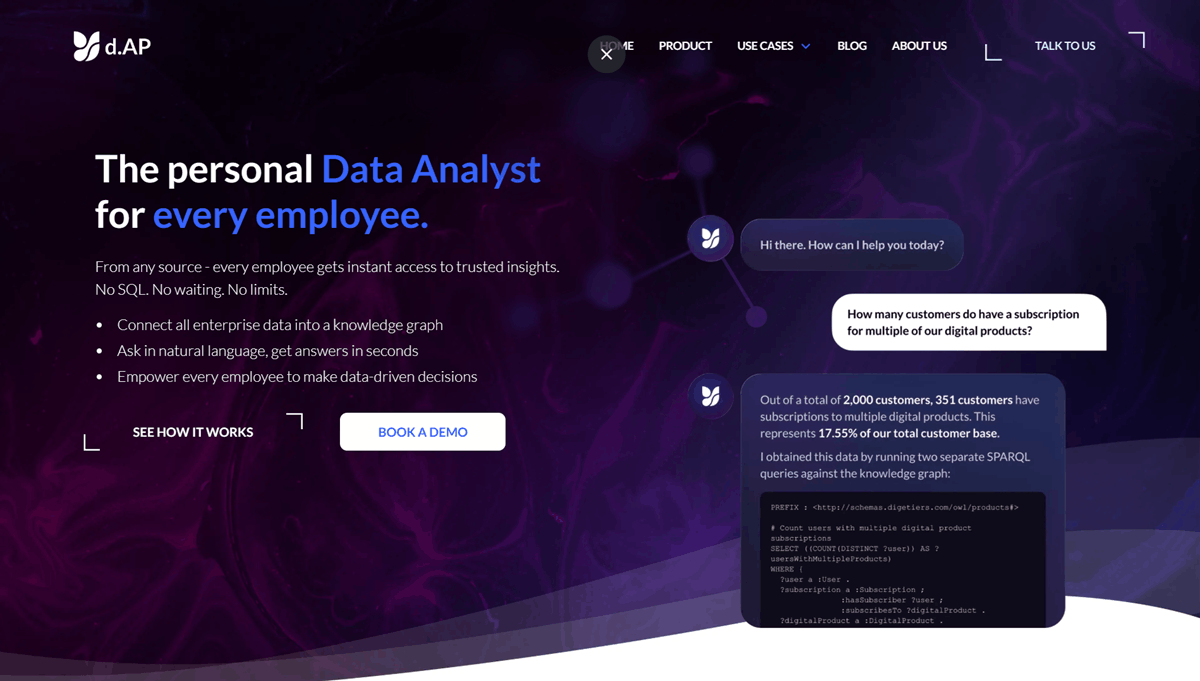
d.AP is a semantic, decision-centric data fabric designed to bridge the gap between raw data and business answers. Unlike traditional integration tools that focus on moving tables, d.AP unifies enterprise data using formal ontology patterns, knowledge graphs, and explainable AI reasoning. It functions as a "Decision Assistant" layer that sits above your existing stack (ERPs, Data Lakes, Warehouses), mapping that data to shared business concepts. This allows organizations to define a metric or rule once and reuse it consistently across dashboards, AI agents, and operational workflows.
Industries best fit: Regulated industries, Automotive, Life Sciences, Energy & Utilities, Manufacturing, Aerospace & Defense.
Best-fit scenarios:
- Cross-system decision intelligence: When you need to answer questions that span SAP, Salesforce, and a Data Lake without moving all the data.
- KPI standardization: Enforcing a single definition of "Margin" or "Risk" across the global enterprise.
- AI-grounded analytics: Providing AI agents with a governed, hallucination-free semantic layer to retrieve facts.
- Knowledge Graph convergence: Programs that need to combine data fabric flexibility with deep semantic reasoning.
Watch-outs: d.AP is not a general-purpose ETL tool for simple data migration. It requires an organization to be serious about semantic ownership - you need to assign owners to your business definitions to get value.
What to test:
- Explainability: Can the platform show the full lineage from the answer back to the source data?
- Logic Reuse: Can a rule defined in d.AP be consumed by both a PowerBI dashboard and a custom AI agent?
- Coexistence: How easily does it map data from your existing Snowflake or Databricks environment?
2. Denodo
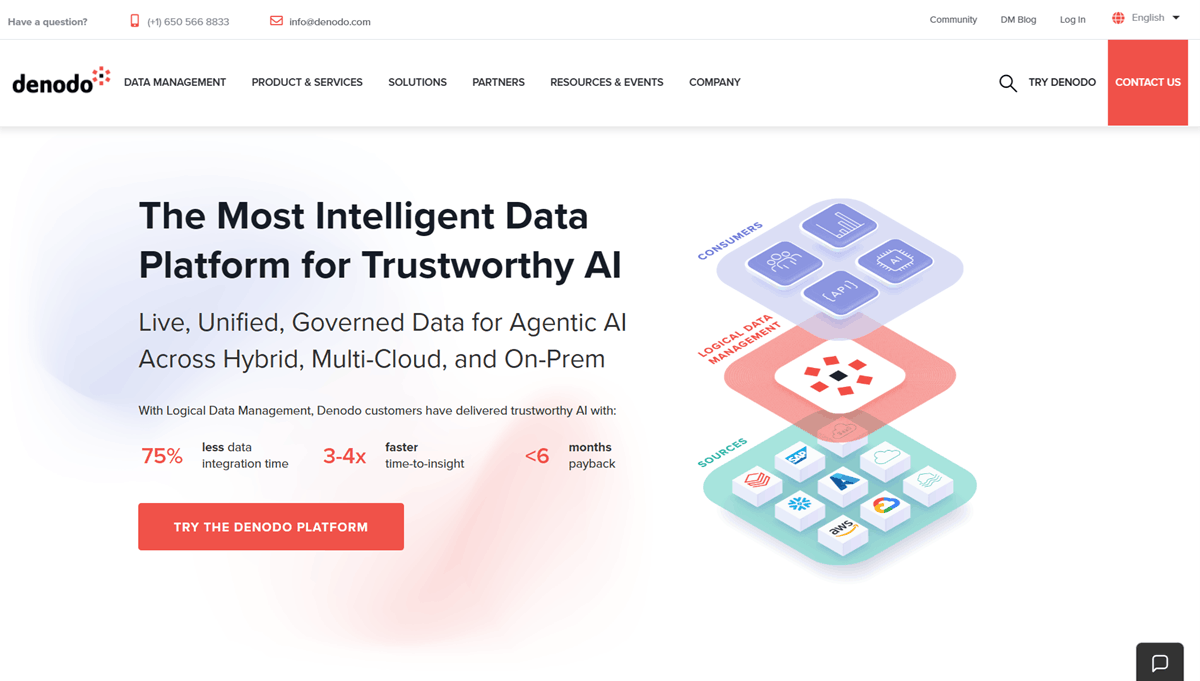
Denodo is the market leader in data virtualization and the standard choice for implementing logical data fabric architectures. Its core philosophy is to leave data where it lives while providing a unified, virtual access layer for consumers. It abstracts the complexity of underlying sources - whether cloud, on-prem, or legacy - allowing developers and analysts to query disparate systems using standard SQL. Denodo excels at high-performance federation, using advanced caching and query optimization to make distributed data feel like a single database.
Industries best fit: Financial Services, Retail, Healthcare, Telecommunications, Government.
Best-fit scenarios:
- Federated Analytics: Enabling BI teams to report across multiple regional warehouses without consolidation.
- Data Residency Compliance: Querying global data without physically moving it across borders.
- Logical Data Warehouse: Creating a unified view of customers across legacy mainframes and modern cloud apps.
- Rapid Prototyping: Testing new data products before building heavy ETL pipelines.
Watch-outs: While powerful for access, Denodo’s semantic capabilities are often limited to "views" rather than deep ontological modeling. Business meaning often remains trapped in the consuming BI tool rather than the fabric itself.
What to test:
- Performance: Run complex joins across high-latency systems to test the query optimizer.
- Governance: Verify that access policies applied in Denodo propagate correctly to the underlying sources.
- Definition Consistency: Test if a metric defined in a Denodo view is easily reusable by non-SQL users.
3. Starburst
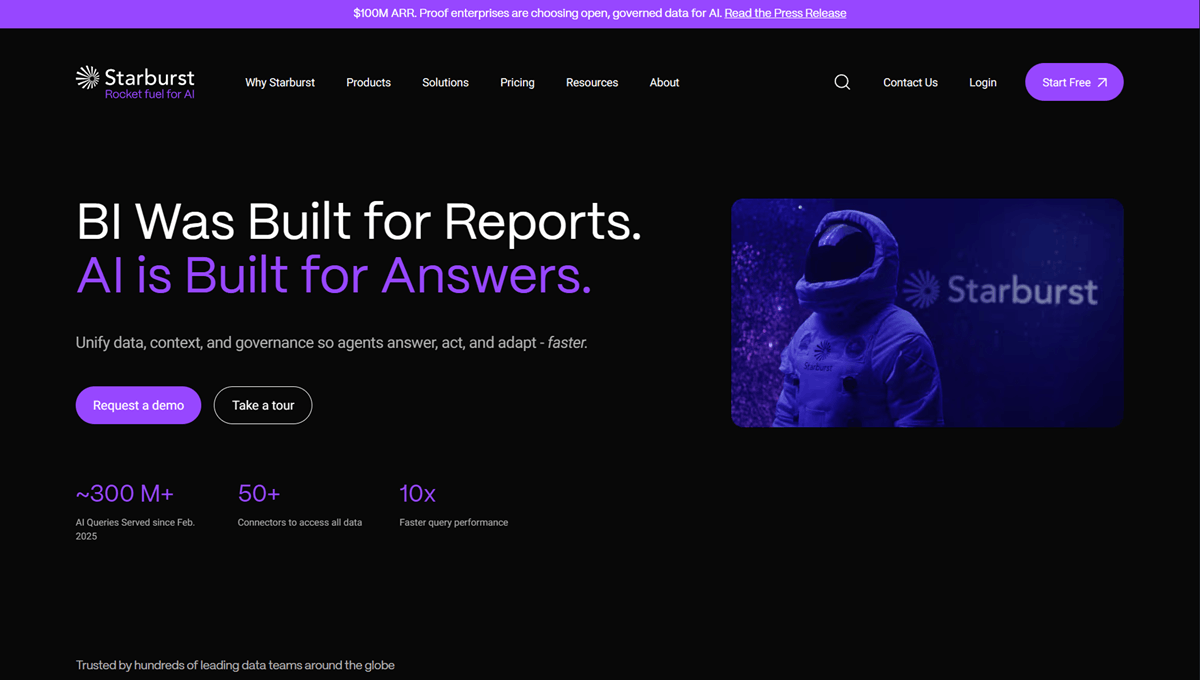
Starburst is a commercial distribution of Trino (formerly PrestoSQL) that powers high-performance, query-centric data fabrics. It is built for speed and scale, allowing organizations to run fast analytical queries across data lakes, warehouses, and operational databases simultaneously. Starburst treats the entire enterprise as a single SQL engine, making it a favorite for data platform teams who need to separate compute from storage. It is particularly strong in "Data Lakehouse" environments where teams want to query open formats (like Iceberg or Delta Lake) directly without ingestion.
Industries best fit: Technology, Media, SaaS, Telecommunications, Data-Intensive Analytics.
Best-fit scenarios:
- Data Lake Analytics: Running high-speed SQL queries directly on S3 or ADLS without loading data into a warehouse.
- Cross-Cloud Analytics: querying data across AWS and Azure simultaneously.
- Ad-hoc Data Science: Giving data scientists a single access point to explore petabytes of distributed data.
- Cost Optimization: Offloading heavy transformation or exploration workloads from expensive proprietary warehouses.
Watch-outs: Starburst is a query engine first. It does not natively manage business semantics or definitions in a user-friendly way. Maintaining KPI consistency across teams requires strong data engineering discipline and external governance tools.
What to test:
- Cost Predictability: Ensure the compute costs for federated queries align with your budget under heavy concurrency.
- Query Governance: Test how well you can manage and audit who is querying what across the distributed landscape.
- Access Controls: Verify fine-grained access control (FGAC) across different file formats and sources.
4. Informatica IDMC

Informatica Intelligent Data Management Cloud (IDMC) is a comprehensive, metadata-driven data management platform. It approaches the data fabric concept through the lens of governance, integration, and master data management. IDMC uses active metadata and AI (CLAIRE) to automate data discovery, lineage, and quality tasks across the enterprise. It is designed for large-scale, complex environments where "knowing what you have" is as important as "moving it." It provides a unified control plane for cataloging, integration, and policy enforcement across hybrid clouds.
Industries best fit: Banking, Insurance, Pharma, Public Sector, Global Manufacturing.
Best-fit scenarios:
- Enterprise Governance Programs: When compliance, lineage, and auditability are the top priorities.
- Complex Migrations: Managing data movement and quality during large-scale cloud migrations.
- Master Data Management: Creating a "golden record" of customer or product data across hundreds of systems.
- Hybrid Integration: Managing legacy on-prem ETL alongside modern cloud pipelines.
Watch-outs: The platform is vast and complex. Time-to-value can be slower compared to lightweight federation tools. It often requires dedicated specialists to configure and maintain effectively.
What to test:
- Runtime vs. Design-time: Does the governance policy actively block a query at runtime, or is it just a documentation artifact?
- Usability: Can a business analyst find and trust a dataset without IT intervention?
- Integration: How seamlessly does it integrate with modern analytics stacks like Snowflake or Databricks?
5. IBM Cloud Pak for Data
IBM Cloud Pak for Data is a modular, platform-centric data fabric solution designed for hybrid and multi-cloud environments. It integrates a wide array of data services - including virtualization, governance, lineage, and AI - into a coherent "fabric" architecture. IBM emphasizes a "connect, don't collect" philosophy, leveraging data virtualization to reduce data movement. It is particularly strong for organizations already invested in the IBM ecosystem (Red Hat OpenShift, DB2, Watson) who need a secure, enterprise-grade layer to manage data across on-premises mainframes and public clouds.
Industries best fit: Banking, Government, Insurance, Telecommunications, Healthcare.
Best-fit scenarios:
- Hybrid Cloud Fabric: connecting on-prem mainframe data with cloud-native applications securely.
- Regulatory Compliance: Environments requiring strict data sovereignty and privacy controls (e.g., GDPR, HIPAA).
- ModelOps: managing the full lifecycle of AI models alongside the data that feeds them.
- Platform Consolidation: Organizations looking to standardize governance and integration on a single vendor stack.
Watch-outs: Platform dependency is the main trade-off. It is a heavy-duty solution that may be overkill for cloud-native startups. Implementation often requires significant architectural planning and effort.
What to test:
- Flexibility: How well does it manage data sources outside of the IBM ecosystem?
- Business Usability: Is the semantic layer accessible to non-technical users, or is it tool-centric?
- Deployment: Test the operational overhead of managing the platform on OpenShift or your chosen cloud.
6. Talend Data Fabric (Qlik)
Talend Data Fabric (now part of Qlik) is an integration-led platform that combines data integration, data integrity, and governance into a single suite. Its data fabric approach is centered on "trust through quality." It focuses on ensuring that data is clean, standardized, and compliant as it moves through the enterprise pipelines. Talend excels at modernizing legacy ETL processes and transforming them into managed, governed data flows. It provides a unified environment for batch, streaming, and API-based integration, making it a versatile choice for engineering-led data teams.
Industries best fit: Retail, Consumer Goods, Manufacturing, Mid-to-Large Enterprise.
Best-fit scenarios:
- Data Quality Initiatives: When the primary pain point is "dirty data" breaking downstream reports.
- ETL Modernization: Moving from brittle, hand-coded scripts to managed, visual pipelines.
- Multi-Cloud Integration: Orchestrating data flows across AWS, Azure, and Google Cloud.
- API Data Services: Exposing data products via APIs for internal application consumption.
Watch-outs: Talend is integration-first, not semantic-first. While it cleans and moves data well, the "business meaning" layer is often lighter than decision-centric fabrics. You may still need a separate semantic layer for consistent metric definitions.
What to test:
- Logic Reuse: Can you apply a data quality rule once and enforce it across all pipelines?
- Lineage: Does the platform provide end-to-end lineage from ingestion to the final report?
- Consumer Fit: How easily can BI tools and AI models consume the trusted data it produces?
How to choose the right data fabric solution
Choosing a data fabric platform is mainly a question of outcomes and constraints, not feature depth. Use the scenarios below to align your shortlist to what you are trying to improve first, then validate the trade-offs you will need to accept.
If your #1 goal is faster analytics
You are likely constrained by the physical movement of data. Your analysts wait for ETL jobs to finish before they can run reports. Prioritize federation and query performance. Look for intelligent caching and query optimization. The trade-off is that you gain speed but must guard against query sprawl.
If your #1 goal is trust and consistency
You are likely constrained by metric drift. Different departments report different numbers for the same KPI. Prioritize semantic modeling and explainability. Look for a strong ontology layer that exists independent of the consumption tool. The trade-off is that this requires organizational discipline to own definitions.
If your #1 goal is AI readiness
You are constrained by the risk of feeding models bad data. You cannot deploy agents because you fear hallucinations. Prioritize governed access, reusable logic, and traceability. Look for platforms that ground AI models in enterprise facts. The trade-off is the upfront investment in metadata management.
Implementation reality check
Unified data fabrics rarely succeed as “big bang” platform rollouts. Let’s look at how they enter the enterprise in practice, including coexistence patterns, ownership, and the fastest path from pilot to durable operating model.
How data fabrics actually enter the enterprise
Successful programs rarely start with a total replacement. They enter as an overlay. Identify a single cross-domain use case where data spans three or more systems. Connect these specific sources without moving the data. Focus on mapping the business concepts for just this domain. Expand to a second domain only after the first delivers value.
Organizational design that works
Technology is often not the barrier; ownership is. A data fabric requires a shift. The platform team should be thin, focusing on security and performance. The business domains must own the meaning of the data. A small governance council arbitrates disagreements. If IT tries to own definitions, the fabric becomes a bottleneck.
Time-to-value playbook
Set realistic expectations. A pilot should connect two or three systems and deliver one actionable workflow in weeks. A full program expands to critical domains over months. Measure success by the reduction in the data engineering backlog and the reduction in KPI disputes, not just the volume of data connected.
Pricing, TCO & effort
Data fabric costs rarely sit only in licensing. Here are the cost drivers and hidden effort, so you can model total ownership, predict operational load, and avoid surprises after the contract is signed.
Cost drivers
Models vary significantly. Compute-based models charge for queries run, which can spike with usage. Capacity-based models charge for infrastructure size, offering predictability. Volume-based models charge for the amount of data connected.
Hidden TCO
The license is only part of the cost. Integration effort determines how much engineering time is needed to maintain views. Governance overhead includes the time required to agree on definitions. Enablement is critical; if business users cannot use the tool, it becomes unused software.
Final thoughts & next steps
Unified data fabrics change how your enterprise runs data work. They shift you from moving data for every new question to reusing access patterns, definitions, and controls across teams. Treat the fabric as an operating model you run and govern, not a tool you install and hope absorbs complexity.
Long-term success depends on meaning and trust. When teams share the same definitions, reuse the same logic, and trace outputs back to source data and rules, decisions move faster. When definitions drift and logic lives inside dashboards or ad hoc SQL, the fabric becomes another layer to reconcile.
Next steps. Pick one cross-domain decision use case with real pressure behind it, such as customer risk, supply disruption, revenue leakage, or compliance reporting. Test your shortlist against that use case end to end. Insist on proof of traceability from result to source, explainability of the logic behind key metrics, and reuse of the same definitions across BI and AI consumption.
If semantics and explainability sit at the centre of your requirements, include d.AP in your evaluation. Compare it head to head with a virtualization-first option on three points: shared definitions, explainable reasoning, and reuse of logic across dashboards and AI workflows.