Your data lake probably isn’t failing because it lacks data.
It may already hold years of structured, semi-structured, and unstructured information. Ingestion works. Storage scales. Lakehouse tooling has improved how your teams manage tables, catalogues, schemas, and compute.
The problem is what happens after the data lands.
When someone asks a cross-domain business question, your teams still have to rebuild the meaning around the data. They need to check which definition of Customer applies, which version of Revenue is trusted, which product hierarchy is current, and which relationships connect the data across systems.
That work doesn’t happen because the lake is broken. It happens because the lake was never designed to carry business meaning on its own.
A data lake knowledge graph adds that missing layer. It sits above the lake and maps raw data to governed concepts, relationships, rules, and definitions. It doesn’t replace your lake or lakehouse investment. It makes the data inside it easier to query, reuse, govern, and safely expose to AI systems.
This is where knowledge graphs enhance data lake efficiency. They reduce repeated joins, manual reconciliation, duplicated business logic, and fragile point-to-point integrations. They also give LLMs, RAG applications, and AI agents a structured context layer instead of asking them to reason over raw, ungrounded tables.
For a broader view of the semantic layer above the lake, see why your data lake needs a semantic layer..
Why the lake plateaus, and what’s actually missing
Before adding anything to the architecture, it’s necessary to analyze why large-scale storage tiers eventually stall. Data lakes don’t plateau because they lack capacity or execution speed; they plateau because nothing within the native storage layer encodes what the data means to the business.
The data swamp is a meaning problem, not a storage problem
A data swamp isn’t just a messy storage layer. It is a lake where metadata, governance, definitions, and business context fail to keep pace with ingestion. A lake can store every file generated by an enterprise and still fail to answer basic business questions.
The root problem behind a data swamp is usually the absence of shared business meaning. A concept like customer means different things across CRM, billing, and support systems. Revenue carries separate calculation logic across sales, finance, and controlling workflows. Similarly, product definitions drift constantly between engineering specifications, manufacturing execution systems, and sales platforms.
This structural limitation is well-documented. A 2024 ScienceDirect survey of semantic data management in lakes concluded that the linkage of metadata to formal knowledge graphs is one of the most studied and effective ways to prevent lakes from degrading into unreadable swamps. The research places this architecture at the critical intersection of ontology-based data access (OBDA) and large-scale physical storage.
Modern lakehouse tooling solves important problems, but not this one
Modern enterprise architectures deploy highly capable tools to manage physical storage complexity. Lakehouse table formats such as Apache Iceberg, Delta Lake, and Apache Hudi have successfully optimized table-level transactions, time-travel querying, and schema evolution. Concurrently, unified data catalogues like Unity Catalog, Polaris, or AWS Glue excel at discovery, basic lineage tracking, and access policy enforcement.
These engineering tools are valuable, but they don’t fully encode business meaning. A data catalogue can tell an enterprise architect where data lives, who owns it, and who can read it. Though, it doesn’t know how one business concept relates to another across domains. The catalog documents the location and security parameters of a table, whereas the knowledge graph maps the overarching semantics of the enterprise. They are complementary, not competing layers, a distinction detailed in our strategic analysis of context graphs and the role of knowledge graphs in modern data intelligence.
AI makes the missing-meaning problem urgent
For decades, experienced human data analysts compensated for weak semantic alignment by applying institutional memory to raw database queries. AI agents, large language models, and automated retrieval systems cannot do that reliably.
When a model queries lake tables directly, it may retrieve relevant records while still misunderstanding definitions, relationship paths, and implicit business rules. This context-layer gap is one reason knowledge graphs are becoming an important foundation for AI-ready data infrastructure.
Industry figures from early 2026 suggest that only about 22% of enterprises rate their internal data as very ready for generative AI integration. Gartner has also predicted that up to 60% of generative AI initiatives unsupported by AI-ready data frameworks will face abandonment through 2026. The implication is simple: without a clear context layer to ground model reasoning, open retrieval pipelines expose autonomous systems to avoidable structural errors.
Four ways a knowledge graph makes the lake more useful
Overlaying a data lake with a knowledge graph changes the operational economics of the storage layer. Rather than relying on abstract marketing promises, this architecture delivers measurable performance gains through four explicit software mechanisms.
1. A shared meaning model that survives schema change
A knowledge graph holds an ontology, which serves as a programmatic model of business concepts, relationships, and rules. This business model gives the lake a stable semantic layer that is completely decoupled from the physical layout of the underlying storage.
Because the logical tier is separated from physical data structures, the data lake can remain highly agile. If a table name changes, a partitioning strategy is altered, or a source system is replaced, the overarching business concepts can remain stable; only the underlying semantic mapping needs an update.
For example, the concept of an Active Customer can be defined once in the ontology and resolved dynamically against CRM tables, billing files, and real-time application usage logs in the lake. Every downstream consumer, including business intelligence dashboards, data science notebooks, and automated RAG pipelines, reuses that same definition instead of wasting time rebuilding it per project. Have a look at this structural alignment in our guide on how ontologies serve as the stable foundation of a knowledge graph.
2. Virtualization and push-down: the graph queries, the lake computes
A modern knowledge graph layer positioned above a data lake doesn’t always require physically moving petabyte-scale data into a dedicated graph database. It virtualizes lake content by mapping graph entities and relationships directly to active tables, files, or object endpoints.
When a consumer issues a query, the semantic layer handles the push-down query compilation. It translates graph query patterns, such as SPARQL or GraphQL, into the optimized native SQL expected by the underlying lake compute engine, whether that is Databricks SQL, Trino, Apache Spark, Athena, or BigQuery. The data lake computes the raw calculation where the files live, and the graph engine interprets the returned relational results. This optimization allows the enterprise to avoid the massive cost and governance liability of a second full copy of lake data while still querying through a business meaning layer.
While real-time data virtualization preserves freshness, certain workloads benefit from materialization. High-frequency reads or small, stable corporate reference data segments are often better off managed via ETL caching within the graph triplestore to optimize query performance and lower compute bills. Balancing these requirements requires a hybrid strategy that combines real-time Zero-ETL mapping with adjustable caching, an architecture explored in our analysis of why semantics, not mass replication, wins in the enterprise.
3. Federation across the lake and the systems around it
An enterprise data lake is rarely the only system in the production environment. Critical corporate information often remains scattered across ERP installations, CRM platforms, manufacturing execution systems (MES), product lifecycle management (PLM) tools, master data management (MDM) solutions, finance frameworks, and legacy warehouses.
A knowledge graph can federate across the data lake and those operational systems through the same unified ontology. Consider a common cross-domain inquiry: “Which specific suppliers contributed to component defects in this product line, and what is our total financial exposure across active customer contracts?” Answering this through standard pipelines requires coordination across five separate systems and multiple engineering teams.
A knowledge graph handles this via a single query that traverses the unified network, operationalizing the academic pattern of ontology-based data access over heterogeneous data. One graph query replaces multiple integration tickets and manual table joins, establishing an architectural model explored further in our guide on [how federated knowledge graphs strengthen enterprise data strategy].
4. Inference: deriving facts the lake never stored
A data lake is built to store explicit facts. A knowledge graph can apply declarative rules at query time to automatically derive new meaning from those facts, executing calculations that were never physically materialized in the storage tier.
If the corporate ontology specifies that Enterprise Customer and Major Account are both subclasses of Top Account, a runtime query for Top Account automatically resolves and aggregates both datasets. These rules can also support real-time compliance tracking, automated customer segmentation, risk classification, and complex product hierarchy logic.
This inference engine eliminates a large class of redundant reconciliation work that would otherwise clutter dbt models, Spark notebooks, and dashboard-specific logic. Because these logical operations are managed declaratively via standard semantic web frameworks like RDF and OWL, the rules become fully inspectable and auditable, allowing the rule itself to serve as the clear explanation for the output.
Technical teams must note that inference isn’t free. Heavy reasoning workloads require careful scoping, indexing, and benchmarking. The primary value is that the architecture supports them natively, shifting the performance burden from brittle pipelines to optimized query efficiency.
Where the knowledge graph sits in your lake stack
A data lake knowledge graph is an additive semantic framework designed to sit cleanly on top of your current data platforms, not replace them. To help enterprise architects visualize this placement, the reference architecture can be broken down into five distinct operational layers.
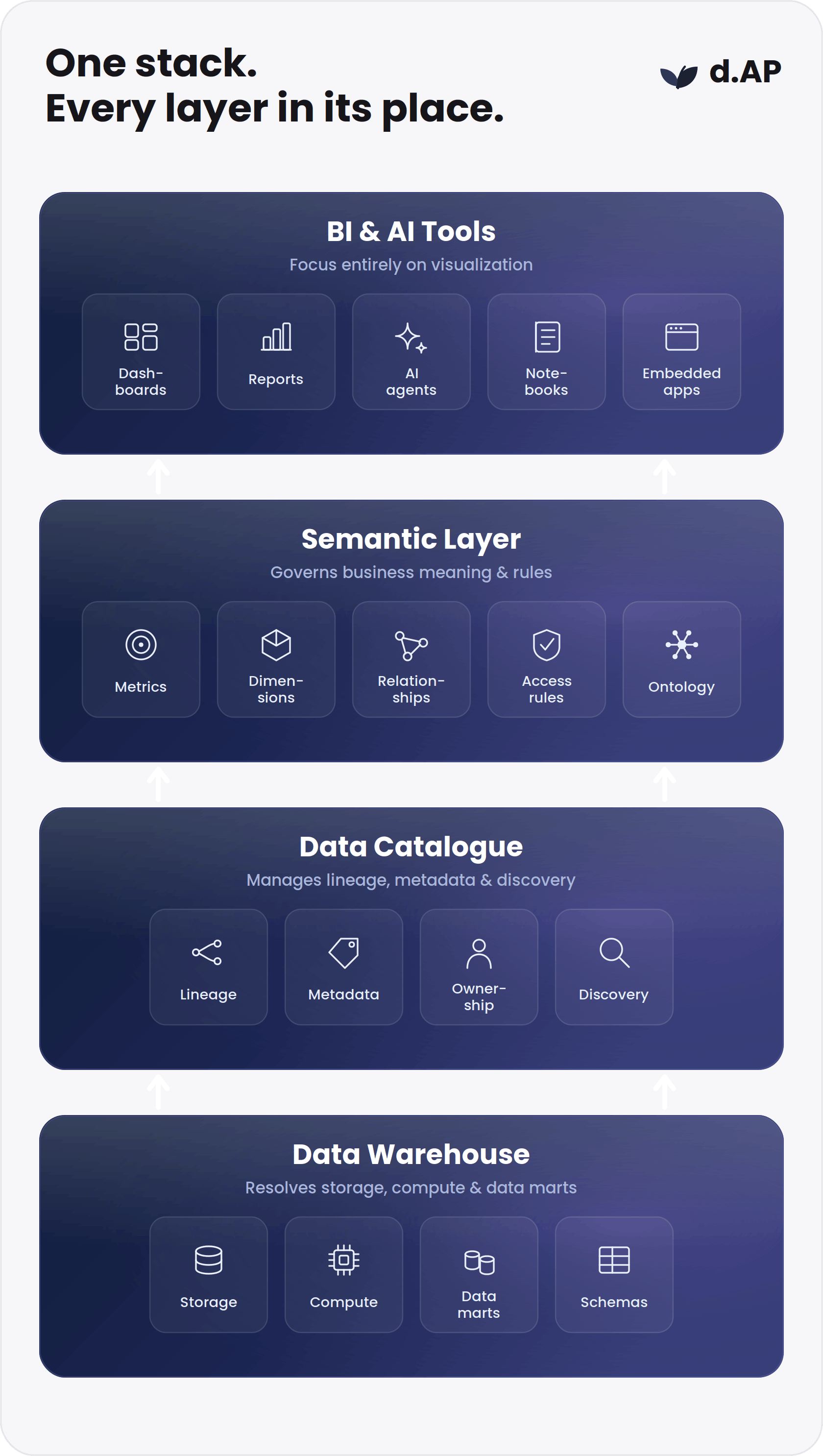
Layer 1: The Storage Substrate
This is the storage layer, consisting of cloud object stores like AWS S3, Azure ADLS, Google Cloud Storage, or mature on-premises filesystems. The knowledge graph leaves this layer completely untouched, honoring your existing investments in low-cost storage.
Layer 2: Table Format and Metadata Catalogue
This tier manages transactional consistency and discovery. Open lakehouse table formats like Apache Iceberg, Delta Lake, or Apache Hudi handle schema evolution and row-level updates, while unified catalogs like Unity Catalog or Polaris manage access policy enforcement and basic table indexing. The graph layer sits completely separate from these components, utilizing them to verify file locations without trying to replace their storage governance capabilities. Data architects can analyze how to avoid common pitfalls when structuring this layer in our evaluation of the zero-copy illusion and multi-platform Iceberg strategies.
Layer 3: Compute and Query Engines
This tier represents the execution engines responsible for processing raw data blocks, including Databricks SQL, Snowflake compute clusters, Trino, Apache Spark, or cloud utilities like Athena. The knowledge graph uses these engines as processing utilities, pushing compiled queries down to them rather than running raw calculations within the graph database itself.
Layer 4: The Knowledge Graph Layer
This is the dedicated semantic control plane. It houses the enterprise ontology, the relationship mapping rules, the inference engine, and the query interfaces. It serves as the single source of business meaning, translating semantic requests into optimized data warehouse or data lake queries while maintaining a global model of corporate context.
Layer 5: Downstream Consumers
This tier represents the application layer, encompassing traditional business intelligence tools, Power BI reports, data science notebooks, custom applications, and autonomous AI agents (like Aluna). Instead of forcing these systems to guess underlying database schemas, they interact directly with Layer 4 through standardized APIs, natural language interfaces, or semantic tools.
How meaning maps to lake data without moving it
The connection between the logical ontology and the physical table formats is established through declarative semantic mappings. Technical teams utilize open standards like the W3C’s RDF Mapping Language (RML) to map out exactly how each ontology class or property connects to specific columns, paths, or data streams inside the lakehouse table format.
This architecture acts as a standard-backed translation tier. A concept such as Compliant Supplier can be mapped simultaneously to physical procurement tables in an Iceberg format, compliance documents in an S3 bucket, and external regulatory risk feeds from a third-party REST API. This structural connection is what transforms your existing data lake into an integrated knowledge graph that serves as the foundation of modern data architecture.
What the knowledge graph does not replace
To maintain a clean architectural footprint, it’s important to be explicit about what the knowledge graph layer doesn’t replace:
- It doesn’t replace the data lake: Storage, physical data modeling, and massive batch-processing workloads remain exactly where they are. The graph is purely additive.
- It does not replace the data catalogue: Catalogues manage technical metadata, physical lineage, table ownership, and file discovery. The graph handles conceptual meaning and business relationships. They sit beside each other, and in mature architectures, they share metadata parameters to improve governance.
- It doesn’t replace the BI semantic layer: A traditional BI semantic layer handles dashboard-specific metric formulas and aggregation logic. A knowledge graph handles entity and relationship meaning for cross-domain reasoning and AI grounding. They are complementary; the metrics layer can consume definitions directly from the underlying graph, as outlined in our guide on integrating knowledge graphs and semantic layers across business intelligence.
What changes once the graph is in place
The value of a data lake knowledge graph shows up clearly when technical mechanisms are translated into measurable business outcomes. Moving to an ontology-backed layer systematically addresses the operational frustrations that cause traditional lake environments to plateau.
Cross-domain questions become faster to answer
Before deploying a graph tier, resolving a cross-domain inquiry requires a data analyst to open multiple tickets, wait for custom data engineering pipelines, and manually stitch together disparate tables. The operational latency is high, often taking weeks to deliver an answer to the business.
After the graph is in place, the cross-domain question becomes a single semantic query. The ontology and built-in inference rules handle the structural reconciliation automatically at query time, pushing the heavy processing down to the relevant lakehouse clusters. Mature implementations show that this relation-driven query efficiency can resolve highly connected questions in a fraction of the time, directly attacking the overhead where knowledge workers spend roughly 20% of their working week simply searching for files across disconnected systems. This acceleration is validated by enterprise benchmarks, where mature graph architectures have demonstrated sub-second query performance over scale targets as large as a trillion edges.
Integration cost drops over time
Traditional data integration scales linearly. Every time a new operational application or file source is added to a centralized lake, engineers must build a fresh set of ETL pipelines and undergo a labor-intensive round of schema alignment to prevent the lake from degrading.
With a knowledge graph lakehouse configuration, the integration dynamic shifts. Each new data source becomes a new declarative mapping into the stable ontology. Because the underlying business concepts are already modeled and verified, the engineering team reuses the existing entities and relationships. This mapping-centric design significantly lowers the marginal cost of onboarding subsequent applications, allowing the data strategy to adapt rapidly to corporate mergers, acquisitions, or system migrations.
Analyst and data engineer productivity improves
Without a shared business vocabulary, data scientists and analytics engineers spend the bulk of their time handling ad-hoc data wrangling and fixing broken transformations. The lack of reusable logic forces teams to rebuild definitions for every new project.
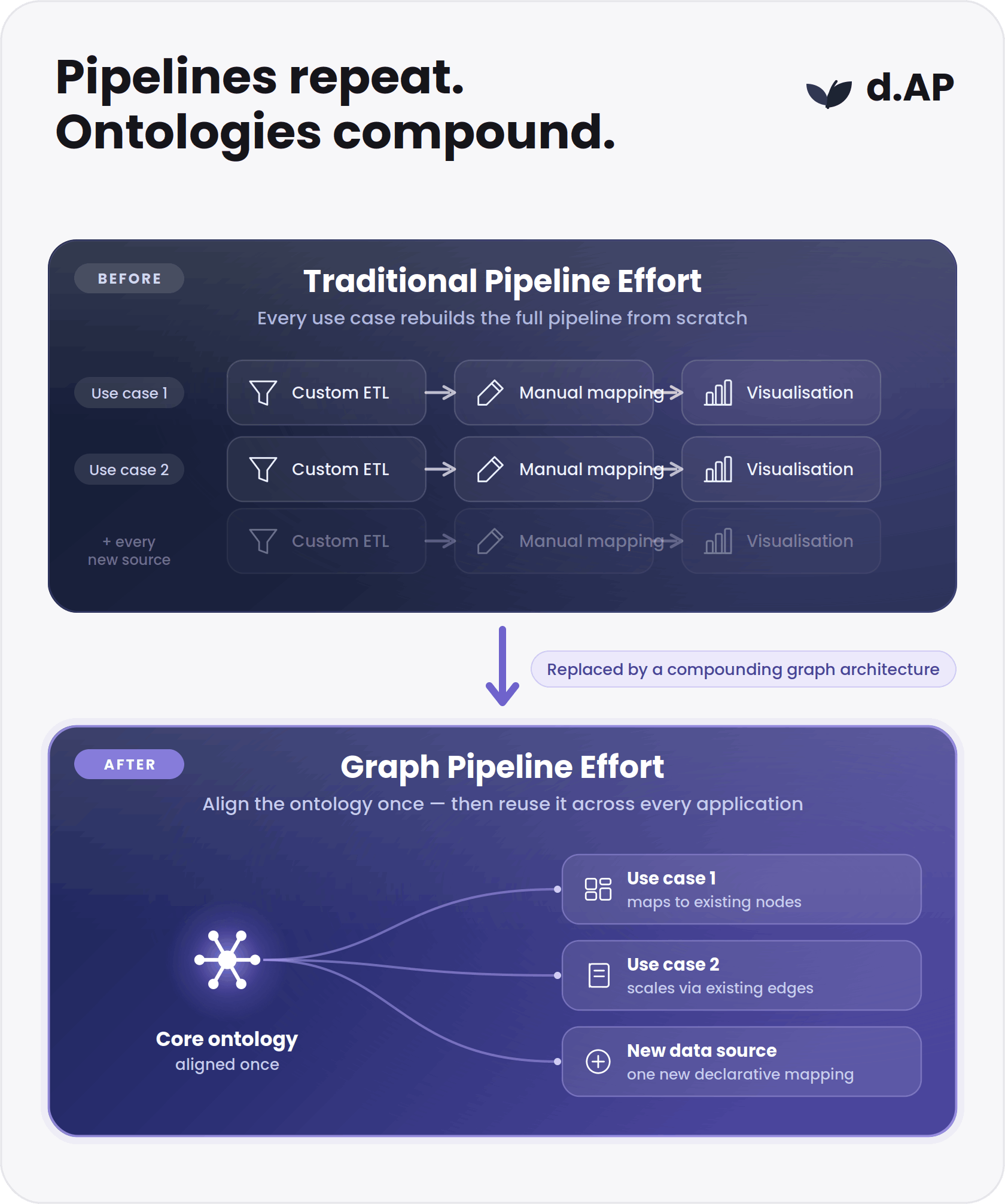
Overlaying the lake with a semantic model improves analyst productivity by providing an immutable, self-service layer of business meaning. Because the data and analytics teams interact with a clear semantic layer rather than raw physical tables, they stop acting as a troubleshooting function for metric definitions. The engineering work moves from maintaining brittle pipelines to extending a reusable corporate asset, embodying the core principles of findable, accessible, interoperable, and reusable data.
Governance and explainability travel with the data
Enterprise data strategies frequently stall in regulated sectors because compliance teams cannot trace the lineage or business logic behind an analytical output. When calculations live inside fragmented dashboards or hidden Spark jobs, verification is difficult to achieve.
A knowledge graph ensures that every answer derived through the control plane carries an implicit audit trail. Every generated number can be traced directly to a specific ontology definition, an active business rule, a clear semantic mapping, and an authoritative source system. For enterprises operating in heavily regulated sectors like finance, pharmaceuticals, manufacturing, and energy, this deterministic explainability is a strict requirement for risk management.
Why AI raises the stakes
The most significant efficiency gain provided by a data lake knowledge graph isn’t found in human analytics. It is found in what changes when automated AI workloads become the dominant consumers of your corporate data lake.
Raw lake data is the wrong substrate for LLMs
Large language models and autonomous agents require grounded, governed business context to execute reasoning workflows safely. A raw data lake provides them with rows, parquet files, unstructured documents, and fragmented database schemas.
When an LLM is forced to query raw storage infrastructure without an intermediary layer, it lacks the context to determine which calculation rules apply or which data relationships are valid. This limitation is exactly why AI projects stall at scale. The model is fine, but the data architecture is missing grammar. With d.AP, the OWL2 ontology layer turns lake-connected data into a structured meaning layer that LLMs and agents can query more safely. Its OWL2 ontology layer transforms lake-connected files into a highly structured meaning layer that LLMs and agents can navigate deterministically.
GraphRAG turns the lake from AI-reachable to AI-readable
Traditional retrieval-augmented generation (RAG) over a data lake works by converting raw text documents into vector embeddings and pulling isolated chunks based on statistical similarity. This approach fails when user queries require multi-hop reasoning or an understanding of cross-domain relationships.
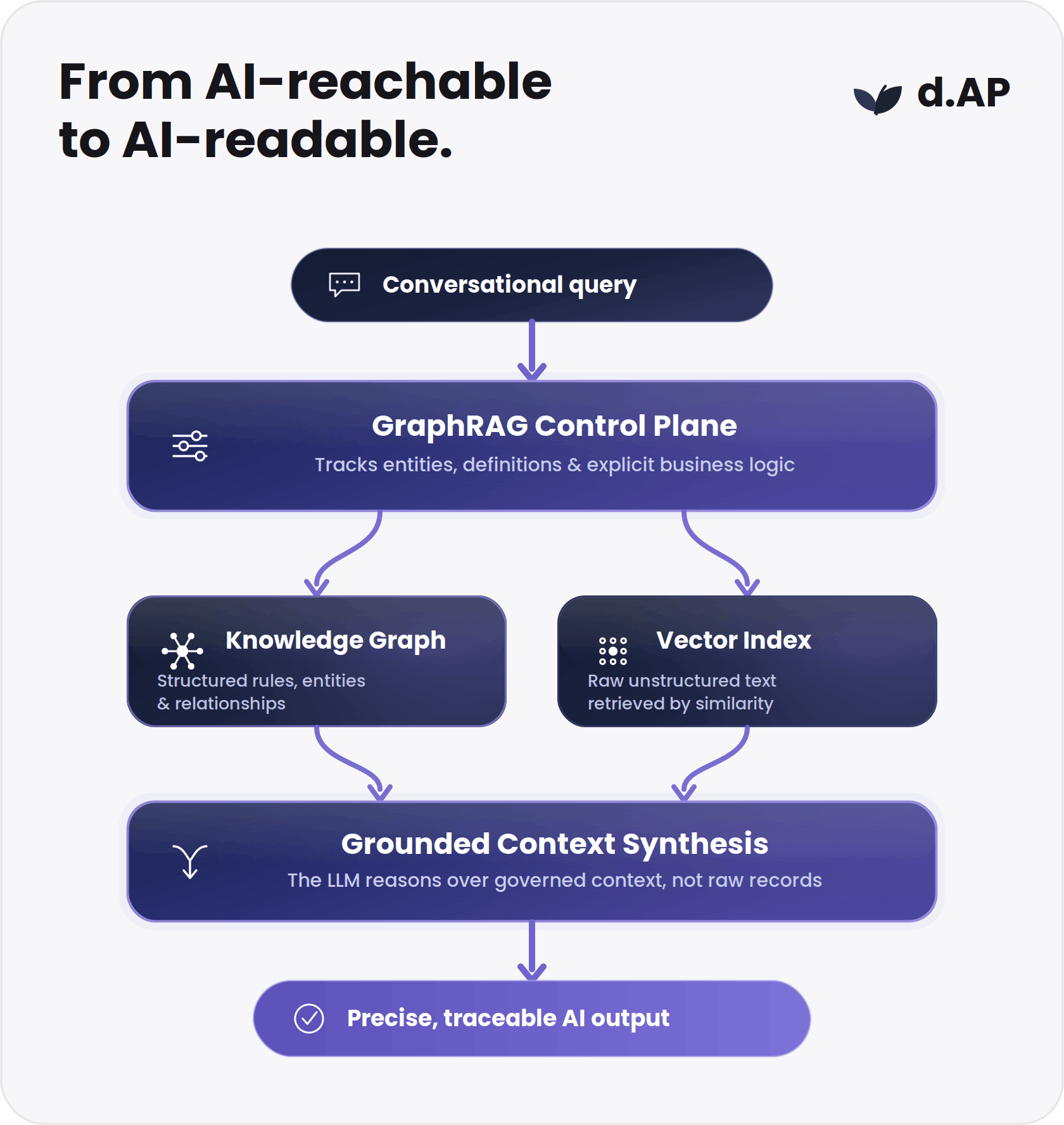
The data lake GraphRAG pattern resolves this limitation by combining structured knowledge graphs with vector indexes. The graph supplies the governed entities, relationships, and business rules, while the vector index manages raw unstructured text blocks. The LLM synthesizes its answer over a grounded context layer rather than guessing connections from raw records.
This model removes the risk of a system opening all the valves to a data lake without an active map to navigate the flood of information. d.AP’s Aluna interface is one example of this pattern: conversational queries are translated into ontology-grounded operations, run across active federators, and returned with the logic and filters applied.
AI agents need a shared vocabulary
As enterprises move beyond isolated chat windows and begin deploying multiple autonomous agents to manage cross-functional workflows, the necessity of a shared vocabulary becomes absolute. If the procurement agent, the finance agent, and the logistics agent all interpret a term like "delivered order" using different operational logic, the automated workflow will collapse.
An ontology provides the shared, machine-readable vocabulary that allows separate agents to coordinate across functional boundaries. It ensures that every automated component shares an identical model of business meaning, providing the necessary infrastructure to scale [AI-powered semantic layers and enterprise data strategy] safely. Technical teams can explore the implementation of these grounding frameworks in our specialized guides on [how to utilize knowledge graphs with LLMs] and our deep dive on [eliminating AI hallucinations in enterprise data infrastructure].
How to start without rebuilding the lake
Transitioning a massive data lake estate to an ontology-backed graph architecture does not require an expensive, disruptive platform migration. Technical leaders can operationalize the pattern using an agile, step-by-step approach.
Start with one cross-domain question
The fastest path to value is to avoid trying to model the entire enterprise on day one. Instead, identify a single, high-leverage cross-domain question that currently takes weeks of manual engineering to resolve.
Targeting explicit operational bottlenecks provides the project with immediate traction. Enterprise teams can focus on a crisp, high-value ontology slice by targeting specific questions:
- Procurement & Operations: Which specific component suppliers create the highest product quality risk based on historical defect logs?
- Commercial Strategy: Which high-value customer accounts are actively affected by a recently discontinued product line?
- Risk & Compliance: Which infrastructure assets are immediately exposed to an upcoming regional regulatory change?
Focusing on questions you cannot answer today, but should be able to, ensures the graph delivers rapid, visible value to the business. Have a look at this initial technical sequence in our Q2 development roadmap on [How to Build a Knowledge Graph for RAG with d.AP].
Use open standards and federation
When selecting your semantic software stack, prioritize open W3C standards like RDF, OWL, SPARQL, and RML. Utilizing open frameworks ensures your corporate definitions remain portable and protected against vendor lock-in.
Furthermore, ensure your chosen platform supports semantic data virtualization and federation by default. Refuse architectures that mandate copying your entire data lake into a separate graph store before delivering value; the graph should query your data where it currently lives.
Treat the catalogue, semantic layer, and graph as one stack
Ensure your deployment plan designs these layers to work as a complementary stack rather than competing utilities. The data catalogue manages the technical metadata, lineage, and physical location of your files. The BI semantic layer governs the explicit dashboard metric formulas and KPIs. The knowledge graph sits as the overarching source of meaning, capturing the entity relationships, structural rules, and ontology required for AI grounding.
Design for AI from day one
Even if your immediate corporate budget is focused entirely on accelerating human analytics or fixing broken reporting definitions, you must design your ontology so that future RAG pipelines and autonomous agents can consume it natively. Retrofitting AI-readiness into an analytics-only graph architecture later is significantly more expensive than building it with open APIs and standard endpoints from the start. You can review how to position this architecture for long-term corporate scaling in our strategic roadmap for Why Every Buy-and-Build Needs a Knowledge Layer.
The lake is infrastructure, the knowledge graph is leverage
A data lake without an independent knowledge graph layer stores everything and explains nothing. It remains a highly performant engineering asset that requires constant manual translation, leaving your organization exposed to metric drift and model hallucinations.
Overlaying your object storage with a flexible graph network transforms raw data rows into a scalable asset of corporate knowledge. It leaves your physical infrastructure investments untouched, acting as the non-disruptive logic tier that makes your data lake accessible, queryable, and auditable across every functional department.
The strategic leverage of this architecture is that it delivers compounding returns. The identical ontology that accelerates cross-domain business analytics today serves as the mandatory grounding layer for the autonomous AI agents your organization will deploy tomorrow.
This is where d.AP’s architecture fits naturally: as a knowledge organization layer above the data lake and surrounding operational systems, designed to make existing infrastructure more productive rather than obsolete.
A productive data lake is no longer the one that stores the most data; it is the one whose meaning layer makes that data immediately usable for the business.