The problem with a data warehouse rarely shows up as missing data.
It shows up in the meeting after the dashboard goes live.
Finance has one revenue figure. Sales has another. Customer success is working from a third version of active accounts. Everyone is pulling from the same warehouse, but each team is applying different business logic on top of it.
That is the access problem a semantic layer solves.
A data warehouse gives your organization a structured place to store, model, and query enterprise data. But it still exposes that data through tables, columns, joins, schemas, and technical query logic. Business users don’t think in those terms. Neither do AI agents, embedded applications, or natural-language analytics tools.
They need governed business meaning.
A semantic layer sits between the warehouse and the tools above it. It translates technical data into shared business definitions, consistent metrics, governed relationships, and reusable access rules. Instead of letting every BI tool, dashboard, notebook, and agent define Revenue, Active Customer, or Gross Margin differently, the semantic layer gives each consumer the same model to work from.
That is what makes a semantic layer in data warehouse architecture so important. It doesn’t make the warehouse less technical. It makes the data inside it easier for the rest of the enterprise to use safely and consistently.
Why your warehouse stores everything but exposes almost nothing
A data warehouse makes enterprise data easier to store, model, and query. But it doesn’t automatically make that data easier for the business to understand.
That’s the gap a semantic layer fills.
Your warehouse knows where the data lives. It knows which tables can be joined. It can process complex queries at scale. But it doesn’t decide what Revenue, Active Customer, Gross Margin, or Contract Value should mean across finance, sales, product, and customer success.
Without a shared layer of business meaning, each team rebuilds that logic for itself.
Tables are not business concepts
Data warehouses expose physical structures: tables, columns, primary keys, foreign keys, dimensional joins, and data marts.
Those structures are essential for processing. They’re not how most people think about the business, though.
A semantic layer maps the technical data in the warehouse to those meaningful business terms. It turns raw columns, joins, and data structures into a model your teams can understand and reuse.
That matters because technical data changes. Table names change. Source systems shift. Data structures evolve. Without a semantic layer, those changes can break downstream reporting and force data teams into another cycle of manual fixes.
With a semantic layer in place, the business concept can stay stable even when the underlying warehouse structure changes. The physical model can evolve without forcing every BI tool, report, and application to reinvent the same definitions.
Metric drift becomes a management problem
Metric drift starts as a technical issue, but it rarely stays there.
If finance, sales, and controlling each define Revenue differently, the problem eventually reaches leadership. The business ends up debating numbers instead of decisions. The issue isn’t always wrong data or broken pipelines. It’s often inconsistent business definitions sitting in different tools.
One team defines revenue in Power BI. Another defines it in Tableau. A data analyst defines it again in a notebook. Each calculation may be technically defensible, but the organization still has three versions of the truth.
A semantic layer makes consistency operational by centralizing business logic in one governed layer. When the definition of Revenue changes, you update it once in the semantic model rather than chasing that logic through every dashboard, report, and query.
That doesn’t remove the need for good data governance. It makes governance easier to enforce because your business context is mapped to BI data through a layer every consumer shares.
Multiple BI tools multiply the problem
Most large organizations don’t rely on one BI tool.
Finance may use Power BI. Sales may use Tableau. Data analysts may use notebooks. Product teams may rely on embedded analytics or custom dashboards.
Without a universal semantic layer, each tool starts building its own local semantic model. That creates local consistency inside each tool, but enterprise-wide drift across the business.
The same metric gets modeled three times. The same join logic gets rewritten. The same access rule gets reimplemented. Data engineers then spend time explaining why numbers disagree instead of building new data products.
A semantic layer gives multiple BI tools one shared model to call from. Each tool can still handle presentation and visualization, but the core definitions, data relationships, and governance rules come from the same place. That is how the warehouse becomes more accessible without letting every tool invent its own meaning.
AI makes the access gap harder to ignore
For years, experienced data analysts could compensate for missing business context. They knew which table to trust, which joins were safe, which filters applied, and which dashboard had the approved number.
AI agents and text-to-SQL systems don’t have that institutional memory.
When an AI system queries raw warehouse schemas directly, it may generate valid SQL and still return the wrong answer. It might choose the wrong revenue field, miss a compliance filter, double-count a relationship, or ignore an access control rule.
That’s why the semantic layer is becoming more than a BI convenience. It’s becoming the context layer future data workloads need.
If AI agents, RAG pipelines, and natural-language analytics tools are going to access warehouse data safely, they need governed definitions, valid relationships, and business rules they can use at query time. A semantic layer provides that structure.
Once you accept that the warehouse stores the data but doesn’t govern its meaning, the next question is practical: what does the semantic layer actually do inside the architecture?
What a semantic layer actually does inside a data warehouse architecture
A semantic layer isn’t just a metadata repository, a business glossary, or a dashboard convenience. It operates as an active, programmatic software tier positioned between the cloud warehouse and every consumer above it, executing four core architectural jobs in real time.
It models the business above the schema
The primary responsibility of the semantic layer is to build an objective, business-centric model that sits completely decoupled from the underlying physical storage tables. This layer holds the authoritative configuration of data entities, business metrics, dimensions, and the valid relationship join paths between them.
While the data warehouse holds a column named fact_orders.net_rev_q, the semantic model defines its full operational reality. It specifies that Net Revenue represents gross revenue minus returns and refunds, scopes it automatically to the fiscal quarter, maps its connection to Customer tables through a verified customer_id, and maps the regional access controls that must be enforced. Every consuming application or agent reads from this business-facing model rather than querying raw schemas directly. Data modeling teams express these relationships through standardized configuration formats, abstracting away complex data structures behind clean business definitions.
It compiles business questions into governed SQL
When a user, an analytics dashboard, or an autonomous agent submits a query for "Revenue by region in Q4," they don’t hand-write raw SQL. The semantic layer ingests the request and dynamically compiles it into the exact, optimized SQL dialect the targeted data warehouse expects.
This compilation engine absorbs structural database complexity instead of forcing it onto the consumer or the application layer. The semantic layer platform evaluates the business logic and automatically resolves mathematical hazards like symmetric aggregates to prevent double-counting revenue across many-to-many relationships. It handles fan-out risk on complex dimensional joins, automates time-grain configurations for metrics like year-to-date or quarter-over-quarter profiles, and pushes optimized queries directly down to the warehouse for execution. This translation capability delivers simplified data access without hiding the processing power of the underlying data platform.
It enforces governance at query time
Traditional data management requires data teams to re-create security rules, row-level filters, and column masking separately within every single dashboard or BI tool. A semantic layer establishes a robust data governance model by applying security policies directly during query compilation.
Because access controls are evaluated at the moment of compilation, governance policies travel natively with the business concepts. For example, if a Customer Lifetime Value metric is accessed through the semantic layer, the system automatically alters the query generation based on the user's data ownership rights: finance receives the full unmasked data, sales sees records restricted to their specific territory, and marketing retrieves only de-identified, aggregated data points. Centralizing security checks at this layer ensures that data consistency and compliance rules are enforced uniformly across the enterprise, regardless of which reporting tools are calling the data.
It serves every consumer through standard interfaces
To function as true enterprise infrastructure, a semantic layer platform should be decoupled from individual visualization vendors. It serves every data consumer by exposing its semantic model through standard, open query interfaces and APIs.
A modern universal semantic layer can simultaneously serve an executive Power BI dashboard using DAX or MDX endpoints, a data science notebook using a REST or GraphQL API, and an AI agent using the Model Context Protocol (MCP). By exposing metrics as standardized tools that applications can call programmatically, the semantic layer eliminates the need for downstream systems to guess database layouts. Gartner’s 2026 D&A Summit commentary points to the same concern, predicting that 60% of agentic analytics projects relying solely on raw AI interfaces, without a consistent semantic model beneath them, will fail by 2028 because they lack the structural grounding required to ensure data quality and trust.
Architecture Pattern: A mature semantic layer sits above platforms such as Databricks or Snowflake, maps physical schemas to business objects, and uses open standards such as RDF, OWL, and SPARQL to avoid creating another lock-in layer.
For example, d.AP, sits above existing warehouse and data platform investments as an ontology-grounded semantic layer, using open standards such as RDF/OWL and SPARQL to expose governed business definitions through REST, MCP, and A2A interfaces.
Once you understand the four operational jobs, the next critical decision is evaluating which semantic layer pattern matches your specific enterprise estate.
The three semantic layer patterns, and where each one fits
A successful semantic layer implementation depends on matching the pattern to your BI landscape, data platform strategy, and AI ambitions. Three distinct semantic architectures have crystallized across enterprise environments. Each approach resolves specific infrastructure constraints, meaning the correct path depends entirely on how your organization accesses data and maps business context.
BI-native: the semantic layer lives inside one BI tool
The BI-native pattern is the historical default for corporate analytics, where metric modeling happens directly inside visualization software like Looker (LookML), Power BI (DAX and Tabular Models), or Tableau Semantics. The metric definitions and join paths live entirely where the dashboards are built and rendered.
The primary strength of this model is its deep, uncompromised integration with the primary visualization interface. Languages like DAX are exceptionally expressive, allowing data analysts to handle complex contextual calculations for business users who interact strictly with corporate dashboards. For teams operating within a single, dominant reporting ecosystem, this approach offers rapid adoption and a lower initial setup cost.
However, the major weakness is that definitions remain locked inside that specific visualization ecosystem. The moment a data notebook, an external application, or a secondary BI tool needs to query the same data warehouse, engineers are forced to manually re-implement the logic. Lifting complex metrics out of a single BI tool requires re-engineering proprietary processing logic, which inevitably triggers enterprise-wide drift.
This pattern is a strong fit when over 90% of your business intelligence runs on one platform and external AI access is not a near-term requirement. Its ultimate failure mode is AI exclusion. Because autonomous agents cannot natively interpret a BI tool's internal semantic configurations, they are forced to write raw SQL against warehouse schemas, resulting in incorrect queries that return wrong answers with high confidence. For example, if a customer-waived exception filter exists only inside a dashboard layer, an AI agent querying the warehouse directly may miss that rule and return an inflated operational performance metric.
Platform-native: the semantic layer lives inside the data platform
With the release of Snowflake Semantic Views and Databricks Unity Catalog Business Semantics, major database vendors have moved to ingest business definitions directly into the storage and processing engine. In this pattern, the semantic layer is co-located directly with your data warehouse storage, compute, and security governance frameworks.
Architecturally, this alignment eliminates the impedance mismatch between the semantic mapping engine and the query compiler. Calculations, lineage tracking, row-level masking, and access controls are evaluated in a single, high-performance database plane. Furthermore, native AI assistants running on the platform can read these embedded business definitions directly, enhancing text-to-SQL accuracy for users interacting with that specific ecosystem. Databricks’ mid-2026 GA release of Unity Catalog Business Semantics highlighted this shift, alongside an open-source release of its core Metric View engine via Apache Spark to help mitigate portability concerns.
The clear trade-off here is vendor lock-in. If your enterprise data strategy spans multi-cloud environments or utilizes a mixed stack, such as operating Snowflake alongside Databricks and BigQuery, platform-native semantics split your business context by platform. A global organization with a mixed database topology ends up needing an additional, independent universal semantic layer anyway to bridge the vendor boundaries. This pattern fits best when you run a single-platform estate, data platform governance is your dominant priority, and your AI applications run almost exclusively on that vendor's built-in assistants.
Universal or headless: the semantic layer is tool-agnostic
The universal semantic layer, often called a headless semantic layer, establishes business logic as an independent architectural tier. Platforms like Cube, AtScale, and the dbt Semantic Layer (MetricFlow) decouple definitions entirely from both the storage engines and the visualization tools, storing metrics as version-controlled code files and exposing them via open APIs.
The definitive advantage of this pattern is greater flexibility across the modern data stack. A single universal semantic layer defines a business concept once in standard YAML or RDF formats and serves it via SQL, REST, GraphQL, MDX, or MCP endpoints to multiple BI tools, data science environments, and autonomous AI agents simultaneously. This architecture is natively aligned with the Open Semantic Interchange (OSI) specification, finalized in early 2026 under the Apache 2.0 license by a coalition including Snowflake, dbt Labs, Databricks, and Salesforce. OSI acts as a vendor-neutral interchange format, ensuring that your core definitions are portable and protected against platform lock-in.
The operational trade-off is that it introduces another distinct piece of infrastructure to run, monitor, and maintain. It demands clear organizational ownership, typically falling to dedicated analytics engineering teams. For small, single-domain estates, a headless semantic layer platform can represent excessive over-engineering. It becomes necessary when your enterprise must support multiple BI tools, spans a multi-platform database estate, builds custom embedded analytics apps, or executes serious agentic AI workflows across diverse data sources.
d.AP as an ontology-grounded universal layer
Within this landscape, d.AP functions as a meaning-grounded variant of the universal semantic layer pattern. Rather than operating as a flat metrics catalog that only tracks KPI calculations, it carries a comprehensive corporate ontology. It maps out foundational business concepts, attributes, formal rules, and data relationships using open W3C standards like RDF and OWL.
This architecture sits above your data warehouse or lakehouse infrastructure rather than trying to replace it. By exposing its model through unified REST, MCP, and Agent-to-Agent (A2A) interfaces, it provides a stable semantic core that outlives individual business intelligence applications or transient language models. To see how a universal meaning tier shapes broader corporate AI strategies, review our framework on [AI-powered semantic layers and enterprise data strategy]. Technical teams can also examine how this independent layer optimizes legacy dashboards in our deep dive on [the semantic layer and its role in business intelligence].
Decoupling your metrics from specific delivery tools lays the groundwork for long-term scalability. This independent positioning becomes mandatory the moment automated machine models begin querying your data platforms directly.
Why AI is forcing the semantic layer decision now
Business users historically tolerated semantic drift and unaligned reports because human data analysts could manually reconcile the conflicting numbers during PowerPoint preparation. Autonomous AI agents don’t possess that human context. They execute data retrieval at machine speed and return functionally wrong data with absolute confidence. This operational risk is why AI workloads have become the primary forcing function for modern semantic layer implementation.
Text-to-SQL over raw schemas fails for predictable reasons
The rapid adoption of generative AI has led many teams to deploy text-to-SQL utilities directly over raw data warehouse tables. These systems frequently generate syntactically flawless SQL that is completely wrong in its business execution.
This failure occurs because raw database schemas lack the tribal knowledge and operational business context required to interpret data correctly. An LLM reading an ungrounded schema cannot determine which calculated fields represent active revenue, which join paths avoid relationship double-counting, or which specific row-level filters match a user's compliance rights. The obstacle is not prompt quality or model sophistication; it is missing semantic infrastructure.
Industry benchmarks make this deficit clear. In a widely cited data.world evaluation, a frontier model like GPT-4 achieved an accuracy rating of just 16.7% when attempting to generate queries directly from raw database schemas. When the exact same model was grounded in a semantic layer that mapped out business definitions and relationships, query accuracy rose to over 54%, demonstrating that a semantic layer for AI is the single highest-leverage component for ensuring data quality.
This structural grounding is what allows technical teams to stop hallucination at scale, as detailed in our guide on enhancing the accuracy of RAG applications with knowledge graphs. This architecture represents a permanent shift from brittle algorithmic guessing to structured corporate reasoning.
Agents should call governed metrics, not guess SQL
To achieve reliable enterprise AI, technical architectures must stop forcing models to guess database layouts and write raw code. Instead, autonomous AI agents and RAG pipelines must interact with the warehouse by calling governed metrics through semantic APIs.
When an agent requests information via an MCP or REST endpoint, the universal semantic layer handles the calculation logic, manages the join path, enforces pre-defined access controls, and executes the compiled SQL query against the data platform securely. This workflow introduces three critical operational properties:
- Absolute Auditability: Every AI-generated number can be linked to a version-controlled metric definition, a specific query path, and an explicit business owner, creating a transparent audit trail for compliance.
- Warehouse Cost Control: Utilizing the aggregate-awareness capabilities of a semantic platform prevents autonomous agents from triggering massive, full-table database scans on simple conversational questions, protecting organizations from runaway compute bills.
- Deterministic Grounding: The model is restricted to interpreting validated data relationships, eliminating the risk of structural calculation errors during runtime.
This pattern is exemplified by d.AP’s Aluna interface. Aluna translates conversational user queries into precise requests against an underlying ontology, executing the generated query and returning an explainable answer that surfaces the exact data source, logic applied, and filters used alongside the numeric response.
The semantic layer is becoming standard infrastructure
The emergence of open, cross-vendor protocols proves that semantic architecture has moved beyond isolated product features. The release of the Open Semantic Interchange (OSI) v1.0 standard under the Apache 2.0 license, championed by a coalition of platform and analytics leaders, marks the transition of the semantic model into a portable corporate asset. Phase two of the initiative targets native configuration ingestion across over 50 enterprise data platforms by the end of 2026.
Concurrently, native MCP endpoints within universal semantic tools allow technical teams to expose metrics directly as structured machine capabilities. The semantic model is no longer a dashboard accessory; it is the universal translation layer that makes the modern data stack AI-readable, not just AI-reachable. Organizations that deploy a portable, standard-backed semantic tier now will own their business definitions, while those that delay will find themselves locked into whichever vendor ecosystem moves fastest.
How to implement a semantic layer without breaking your warehouse stack
Implementing a semantic layer shouldn’t begin with a platform decision. It should begin with the definitions the business already argues about. Transitioning a complex warehouse topology to a decoupled semantic tier requires a predictable, staged delivery plan that avoids disruptive rip-and-replace software mandates.
Start with the metrics executives already reconcile manually
Engineering teams frequently fail during implementation by attempting to model the entire corporate data warehouse schema from day one. This over-scoping paralyzes the project in perpetual design reviews. A defensible implementation path focuses strictly on isolating the 20 to 50 high-value business metrics that drive executive governance, including Revenue, Gross Margin, Active Customers, and Churn Rate.
Targeting the explicit inventory of manual disagreements within your reporting layer provides the project with immediate structural funding. The time spent by data analysts manually auditing why the sales pipeline view does not reconcile with financial accounting sheets represents the exact cost line being reclaimed. Demonstrating a successful semantic layer implementation across just three core metrics in an executive dashboard establishes organizational trust far more effectively than producing an extensive, unused metadata repository.
Pick the architecture pattern that matches the estate
Selecting among different types of semantic layers must follow an objective architectural rule rather than vendor marketing. Organizations can map their logic according to three strict deployment parameters:
- BI-Native Deployment: Choose this path if over 90% of all corporate consumption is contained within a single tool like Power BI and automated AI agents are explicitly excluded from the multi-year technology roadmap.
- Platform-Native Deployment: Select this model if your data infrastructure is completely unified under a single cloud database vendor and global governance compliance represents your overriding technical priority.
- Universal or Headless Deployment: Implement this decoupled pattern if your environment operates multiple BI tools, crosses multi-cloud data warehouses, features custom embedded web applications, or requires an active semantic layer for AI.
Pragmatic enterprise architectures routinely deploy a hybrid variant of these patterns. A universal semantic layer platform serves as the canonical hub of business meaning, while thin, BI-native configurations extract subsets of that logic to support tool-specific visualization details. Consistency is preserved because the central model remains the governed authority for data definitions.
Treat semantics as code
To prevent the business logic layer from becoming another obscured configuration silo, all metric expressions, dimensions, and relationship join paths must be managed with software engineering rigor. Definitions belong in version-controlled repositories, where every alteration passes through structured peer review workflows, regression testing, and CI/CD pipelines.
Adopting configuration parameters that align natively with the emerging Open Semantic Interchange (OSI) standard guarantees long-term portability. Defining data modeling schemas in standard, portable YAML files helps decouple your enterprise from vendor software roadmaps. When metrics are treated as code, your business context is insulated from platform migrations, allowing semantic assets to scale alongside evolving data platform infrastructure.
Keep the warehouse, catalogue, and BI tools doing what they do well
A semantic layer doesn’t compete with the components of your modern data stack; it acts as the logical connective tissue that enhances them. Data teams must maintain strict operational boundaries between these layers:
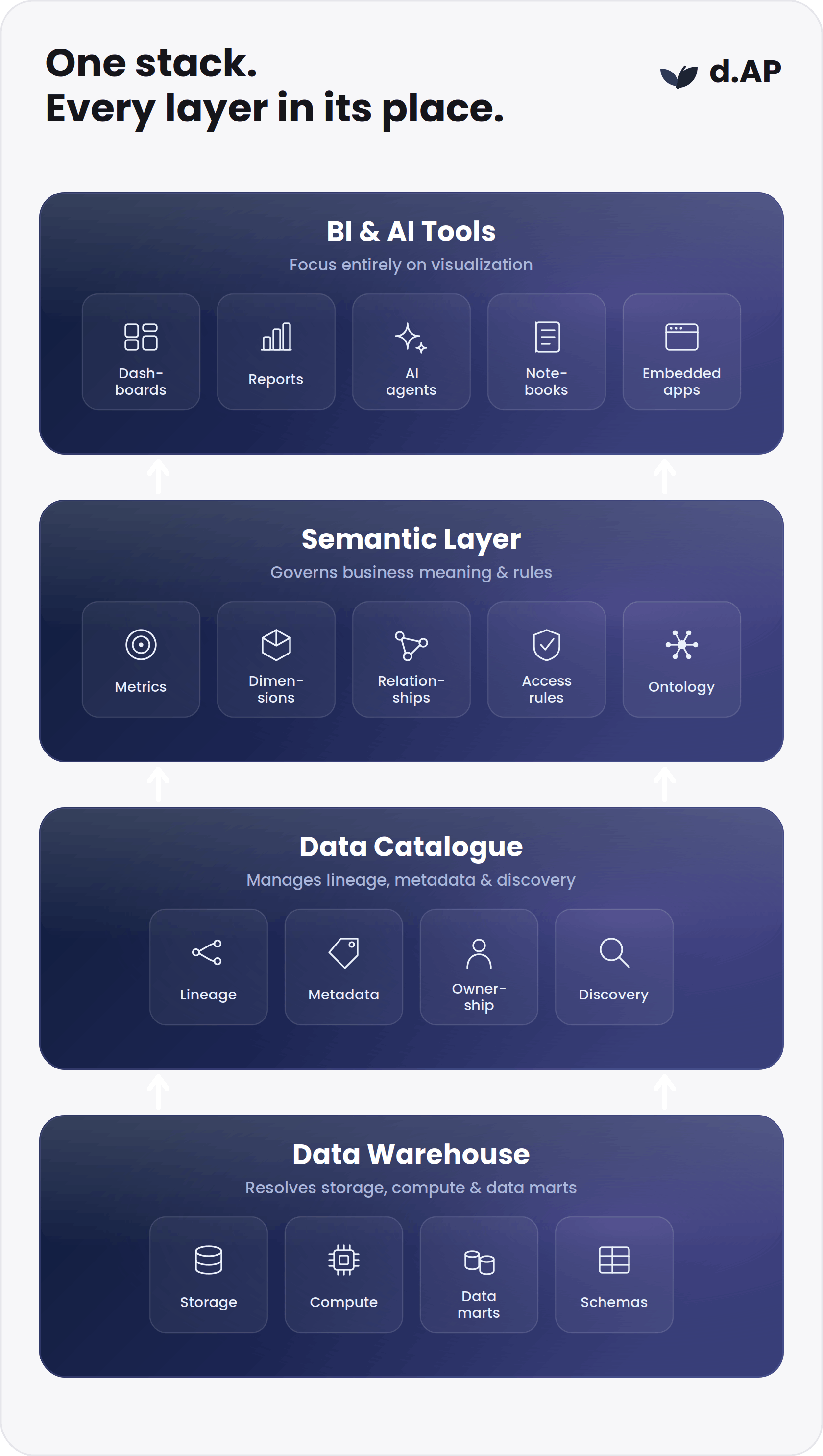
The data warehouse remains the dedicated substrate for physical data management, high-volume ingestion processing, and raw compute operations. The data catalogue functions as a structural metadata repository, tracking data lineage, asset ownership, and semantic discovery across distributed environments. A familiar heuristic applies: the data catalogue tells your data engineers where data lives, while the semantic layer dictates what that data means to your business users. Visualization tools continue to focus on presentation layout, freed from the liability of hardcoding calculation rules.
The warehouse stores data, but the semantic layer makes it accessible
A cloud data warehouse without a semantic model is highly usable by data engineers, but still difficult for the rest of the enterprise. Exposing raw tables forces downstream users and machine systems to interpret schemas, joins, and business logic that should already be governed.
BI-native, platform-native, and universal semantic layers are not maturity stages. There are different architectural patterns for different estates. The right choice depends on whether your corporate definitions need to live inside one BI tool, one data platform, or an independent layer that serves multiple tools, applications, and AI agents.
That choice has become urgent as future data workloads shift from human analysts to autonomous AI systems. Human workers could absorb some friction from unaligned reports. AI agents querying raw data warehouses can generate calculation errors at machine speed.
As an ontology-grounded knowledge layer above existing cloud data infrastructure, d.AP fits naturally as a tool-agnostic deployment. Using open RDF, OWL, and SPARQL standards, it exposes a consistent model of meaning to BI tools, applications, and agents.
The path toward an accessible data estate doesn’t require a multi-quarter platform overhaul. It starts with the business metric whose unified definition makes the next two easier to justify.